MYSQL索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
普通索引
创建索引
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
CREATE INDEX indexName ON mytable(username(length));
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName)
创建表的时候直接指定
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
删除索引的语法
DROP INDEX [indexName] ON mytable;
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
创建索引
CREATE UNIQUE INDEX indexName ON mytable(username(length))
修改表结构
ALTER table mytable ADD UNIQUE [indexName] (username(length))
创建表的时候直接指定
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
UNIQUE [indexName] (username(length))
);
使用ALTER 命令添加和删除索引
有四种方式来添加数据表的索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list):
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list):
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list):
添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):
该语句指定了索引为 FULLTEXT ,用于全文索引。
以下实例为在表中添加索引。
mysql> ALTER TABLE testalter_tbl ADD INDEX (c);
你还可以在 ALTER 命令中使用 DROP 子句来删除索引。尝试以下实例删除索引:
mysql> ALTER TABLE testalter_tbl DROP INDEX c;
使用 ALTER 命令添加和删除主键
主键只能作用于一个列上,添加主键索引时,你需要确保该主键默认不为空(NOT NULL)。实例如下:
mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL;
mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i);
你也可以使用 ALTER 命令删除主键:
mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY;
删除主键时只需指定PRIMARY KEY,但在删除索引时,你必须知道索引名。
显示索引信息
你可以使用 SHOW INDEX 命令来列出表中的相关的索引信息。可以通过添加 \G 来格式化输出信息。
尝试以下实例:
mysql> SHOW INDEX FROM table_name; \G
........
MySQL 临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。临时表在MySQL 3.23版本中添加,如果你的MySQL版本低于 3.23版本就无法使用MySQL的临时表。不过现在一般很少有再使用这么低版本的MySQL数据库服务了。
MySQL临时表只在当前连接可见,如果你使用PHP脚本来创建MySQL临时表,那每当PHP脚本执行完成后,该临时表也会自动销毁。
如果你使用了其他MySQL客户端程序连接MySQL数据库服务器来创建临时表,那么只有在关闭客户端程序时才会销毁临时表,当然你也可以手动销毁。
实例
以下展示了使用MySQL 临时表的简单实例,以下的SQL代码可以适用于PHP脚本的mysql_query()函数。
mysql> CREATE TEMPORARY TABLE SalesSummary (
-> product_name VARCHAR(50) NOT NULL
-> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00
-> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00
-> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO SalesSummary
-> (product_name, total_sales, avg_unit_price, total_units_sold)
-> VALUES
-> ('cucumber', 100.25, 90, 2);
mysql> SELECT * FROM SalesSummary;
+--------------+-------------+----------------+------------------+
| product_name | total_sales | avg_unit_price | total_units_sold |
+--------------+-------------+----------------+------------------+
| cucumber | 100.25 | 90.00 | 2 |
+--------------+-------------+----------------+------------------+
1 row in set (0.00 sec)
当你使用 SHOW TABLES命令显示数据表列表时,你将无法看到 SalesSummary表。
如果你退出当前MySQL会话,再使用 SELECT命令来读取原先创建的临时表数据,那你会发现数据库中没有该表的存在,因为在你退出时该临时表已经被销毁了。
删除MySQL 临时表
默认情况下,当你断开与数据库的连接后,临时表就会自动被销毁。当然你也可以在当前MySQL会话使用 DROP TABLE 命令来手动删除临时表。
以下是手动删除临时表的实例:
mysql> CREATE TEMPORARY TABLE SalesSummary (
-> product_name VARCHAR(50) NOT NULL
-> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00
-> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00
-> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO SalesSummary
-> (product_name, total_sales, avg_unit_price, total_units_sold)
-> VALUES
-> ('cucumber', 100.25, 90, 2);
mysql> SELECT * FROM SalesSummary;
+--------------+-------------+----------------+------------------+
| product_name | total_sales | avg_unit_price | total_units_sold |
+--------------+-------------+----------------+------------------+
| cucumber | 100.25 | 90.00 | 2 |
+--------------+-------------+----------------+------------------+
1 row in set (0.00 sec)
mysql> DROP TABLE SalesSummary;
mysql> SELECT * FROM SalesSummary;
ERROR 1146: Table 'RUNOOB.SalesSummary' doesn't exist
MySQL 复制表
如果我们需要完全的复制MySQL的数据表,包括表的结构,索引,默认值等。 如果仅仅使用CREATE TABLE … SELECT 命令,是无法实现的。
本章节将为大家介绍如何完整的复制MySQL数据表,步骤如下:
- 使用 SHOW CREATE TABLE 命令获取创建数据表(CREATE TABLE) 语句,该语句包含了原数据表的结构,索引等。
- 复制以下命令显示的SQL语句,修改数据表名,并执行SQL语句,通过以上命令 将完全的复制数据表结构。
- 如果你想复制表的内容,你就可以使用 INSERT INTO … SELECT 语句来实现。
实例
尝试以下实例来复制表 runoob_tbl 。
步骤一:
获取数据表的完整结构。
mysql> SHOW CREATE TABLE runoob_tbl \G;
*************************** 1. row ***************************
Table: runoob_tbl
Create Table: CREATE TABLE `runoob_tbl` (
`runoob_id` int(11) NOT NULL auto_increment,
`runoob_title` varchar(100) NOT NULL default '',
`runoob_author` varchar(40) NOT NULL default '',
`submission_date` date default NULL,
PRIMARY KEY (`runoob_id`),
UNIQUE KEY `AUTHOR_INDEX` (`runoob_author`)
) ENGINE=InnoDB
1 row in set (0.00 sec)
ERROR:
No query specified
步骤二:
修改SQL语句的数据表名,并执行SQL语句。
mysql> CREATE TABLE `clone_tbl` (
-> `runoob_id` int(11) NOT NULL auto_increment,
-> `runoob_title` varchar(100) NOT NULL default '',
-> `runoob_author` varchar(40) NOT NULL default '',
-> `submission_date` date default NULL,
-> PRIMARY KEY (`runoob_id`),
-> UNIQUE KEY `AUTHOR_INDEX` (`runoob_author`)
-> ) ENGINE=InnoDB;
Query OK, 0 rows affected (1.80 sec)
步骤三:
执行完第二步骤后,你将在数据库中创建新的克隆表 clone_tbl。 如果你想拷贝数据表的数据你可以使用 INSERT INTO… SELECT 语句来实现。
mysql> INSERT INTO clone_tbl (runoob_id,
-> runoob_title,
-> runoob_author,
-> submission_date)
-> SELECT runoob_id,runoob_title,
-> runoob_author,submission_date
-> FROM runoob_tbl;
Query OK, 3 rows affected (0.07 sec)
Records: 3 Duplicates: 0 Warnings: 0
执行以上步骤后,你将完整的复制表,包括表结构及表数据。
另一种完整复制表的方法:
CREATE TABLE targetTable LIKE sourceTable;
INSERT INTO targetTable SELECT * FROM sourceTable;
其他:
可以拷贝一个表中其中的一些字段:
CREATE TABLE newadmin AS
(
SELECT username, password FROM admin
)
可以将新建的表的字段改名:
CREATE TABLE newadmin AS
(
SELECT id, username AS uname, password AS pass FROM admin
)
可以拷贝一部分数据:
CREATE TABLE newadmin AS
(
SELECT * FROM admin WHERE LEFT(username,1) = 's'
)
可以在创建表的同时定义表中的字段信息:
CREATE TABLE newadmin
(
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY
)
AS
(
SELECT * FROM admin
)
区分下mysql复制表的两种方式。
第一、只复制表结构到新表
create table 新表 select * from 旧表 where 1=2
或者
create table 新表 like 旧表
第二、复制表结构及数据到新表
create table新表 select * from 旧表
主要配置文件
二进制文件日志log-bin
主从复制
错误日志log-error
默认是关闭的,记录严重的警告和错误信息,每次启动和关闭的详细信息等
查询日志log
默认关闭,记录查询的sql语句,如果开启会减低mysql的整体性能,因为记录日志也是需要消耗系统资源的
数据文件
库
默认路径: /var/lib/mysql
frm文件
存放表结构
MYD文件
存放的是数据,DATA
MYI文件
存放的是查找数据的索引,INDEX
逻辑结构
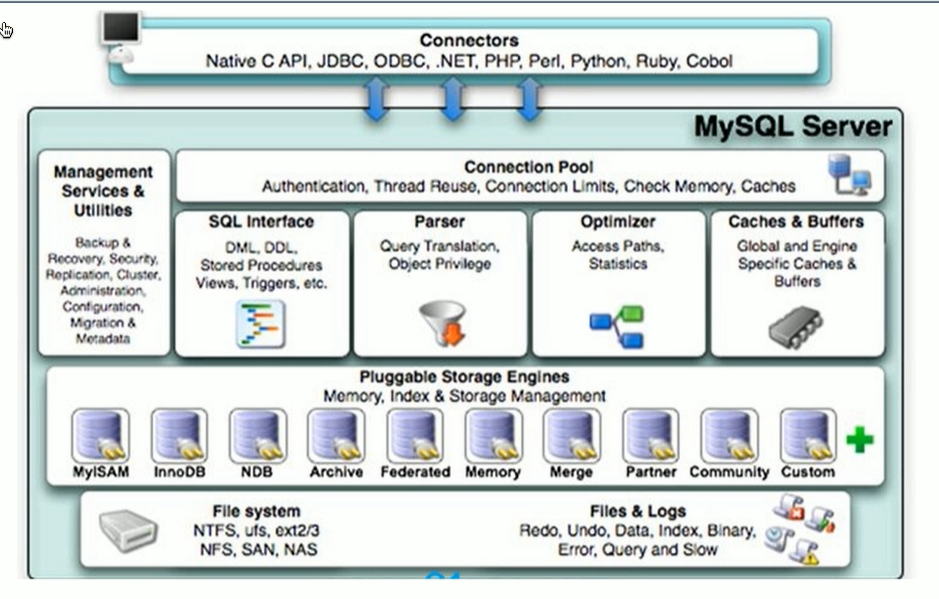



存储引擎
show enigines
查看mysql当前默认的存储引擎
show variable like '%storage_engine%'
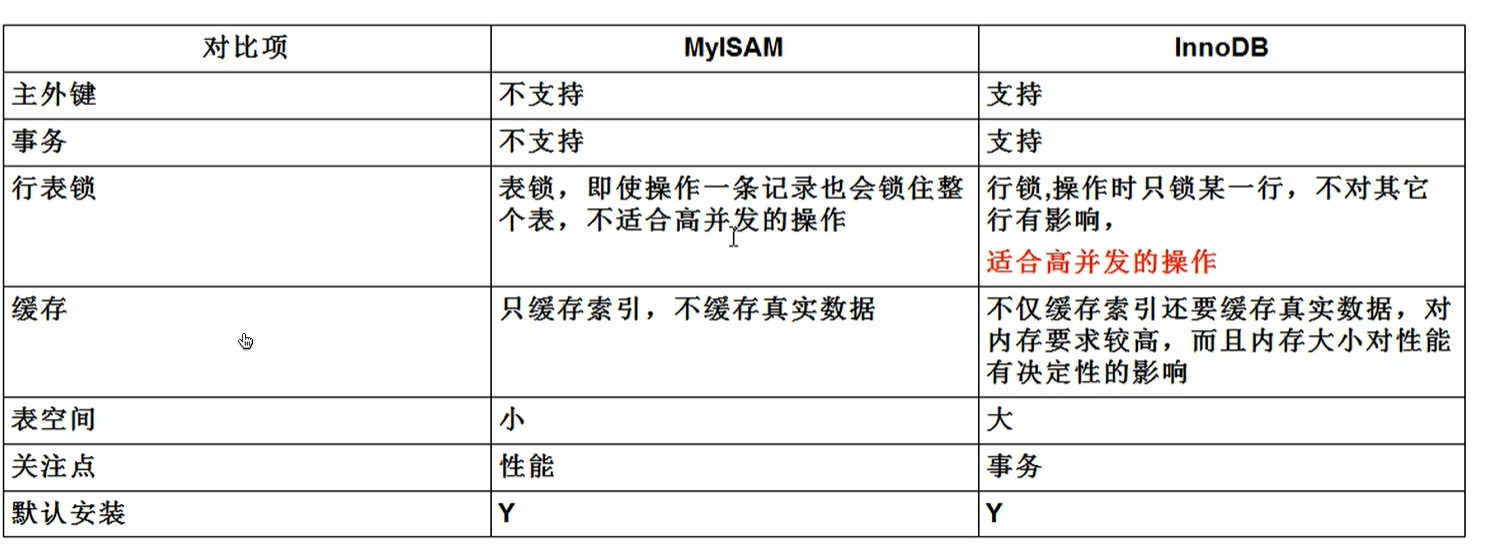
MyisAm和InnoDB区别

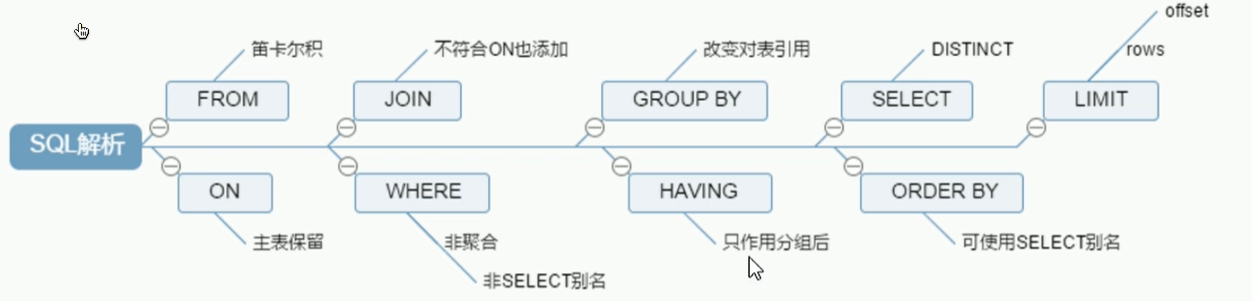
SQL执行加载顺序
手写

机读
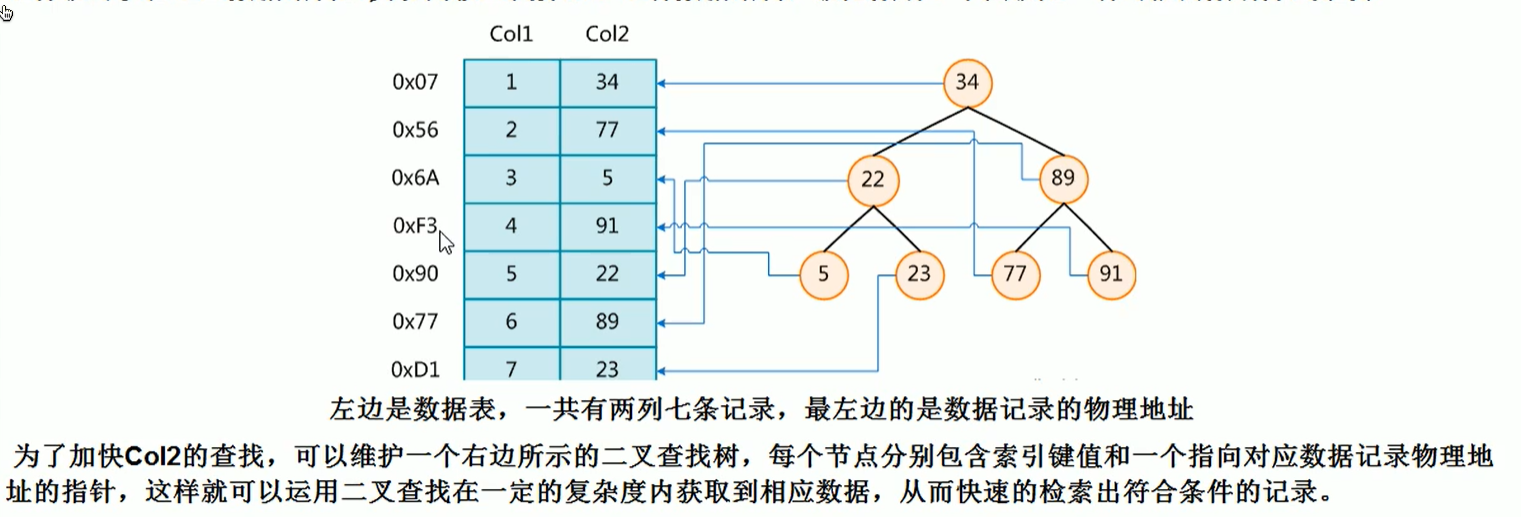
索引
MYSQL官方对索引的定义:索引(Index)是帮助MYSQL高效获取数据的数据结构.可以得到索引的本质:索引就是数据结构.
“排好序的快速查找数据结构” 对排序和查找都有影响
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据.
这样可以在这些数据结构上实现高级查找算法.这种数据结构,就是索引.下图就是一种可能的索引方式示例:
索引的目的在于提高查找效率,可以类比字典;
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上
我们平常所说的索引,如果没有特别指明,都是指b+树(多路搜索树,并不一定是二叉的)结构组织的索引,其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引.当然,除了B+树这种类型的索引之外,还有哈希索引(hash index)等
索引优势
类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本,通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗.
劣势

索引的分类
单值索引
即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引
索引列的值必须唯一,但允许有空值
复合索引
即一个索引包含多个列
索引的命名语句
创建
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON (columnname(name));

删除
DROP INDEX [indexName] ON mytable;
查看
SHOW INDEX FROM table_name\G
使用ALTER命令
索引结构
BTree索引
b+树
Hash索引
full-text全文索引
R-Tree索引
哪些情况需要创建索引?
- 主键自动创建索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引,因为每次更新不单单是更新了记录还会更新索引
- where条件里用不到的字段不创建索引
- 单键/组合索引的选择问题(在高并发下倾向创建组合索引)
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组的字段
哪些情况不需要创建索引?
表记录太少
经常增删改的表
提高了查询速度,同时会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。
因为在更新表时,MYSQL不仅要保存数据,还要保存一些索引文件。
数据重复且分布均匀的表字段,因此应该只为最经常查询和最经常排序的数据建立索引。
如果某个数据列包含许多重复内容,为它建立索引就没有太大的实际效果。

性能分析(查询执行计划)
MYSQL QUERY Optimizer

MYSQL的常见瓶颈

Explain

能干吗
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 那些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
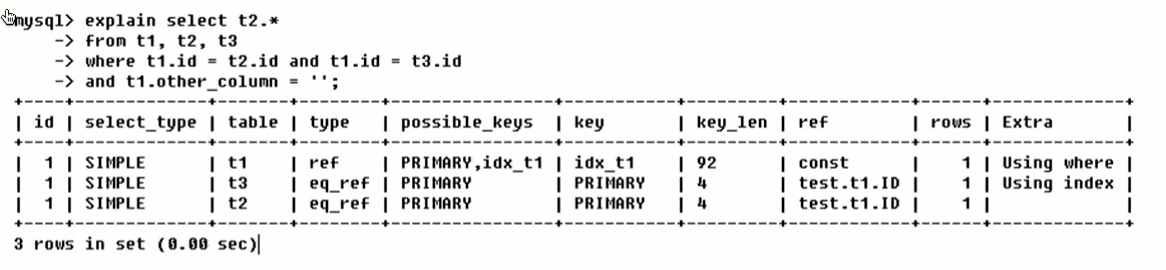
使用:Explain + SQL语句
执行计划包含的信息

表的读取顺序
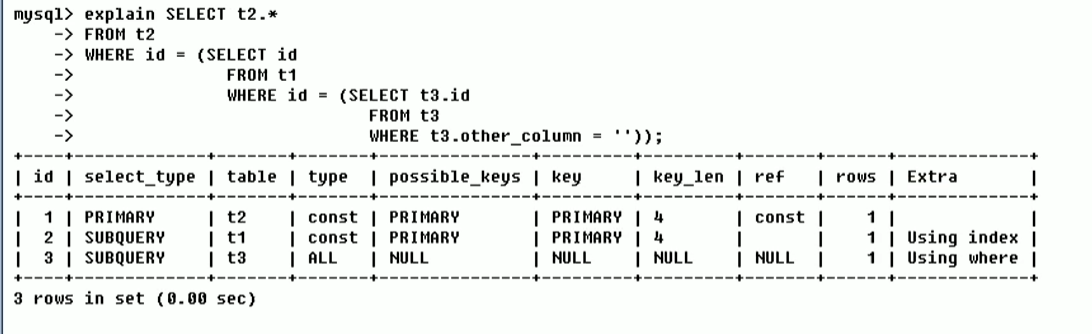
id:
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
三种情况:
id相同,执行顺序由上至下
id不同,如果是子查询,id的序号会递增,id值越大优先级会越高,越先被执行.
id相同不同,同时存在
derive的2指的是id为2的t3.

数据读取操作的操作类型
select_type:
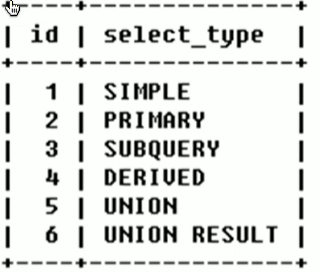

table:
显示这一行数据是关于哪张表的
type:
访问类型

显示查询使用了何种类型,
从最好到最差依次是:
system > const > eq_ref > ref > range > index >ALL

system

const

eq_ref

ref

range

index

ALL
全表扫描


possible_keys 和 key:
possible_keys:

key:

key_len:

4(char长度)*3(UTF-8)+1(null)=13
ref:


rows:

extra:
包含不适合在其他列中显示但十分重要的额外信息
Using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,MYSQL中无法利用索引完成的排序操作被称为"文件排序"
Using temporary
Using index
覆盖索引,在possible_keys没有出现但在key出现
覆盖索引:
Using where
使用了where过滤
using join buffer
使用了连接缓存
impossiable where
where子句的值总是false,不能用来获取任何元组
select tables optimized away
在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化.
distinct
优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作。





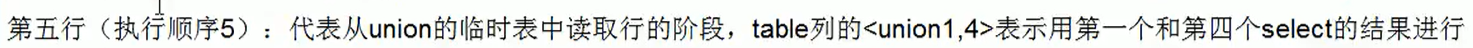
单表优化


范围使索引失效


两表优化

先尝试只添加右表的索引


左表


所以左连接要加右表。左表全有,加不加索引都是全表查询。
三表优化



索引优化
避免索引失效
建表


全值匹配

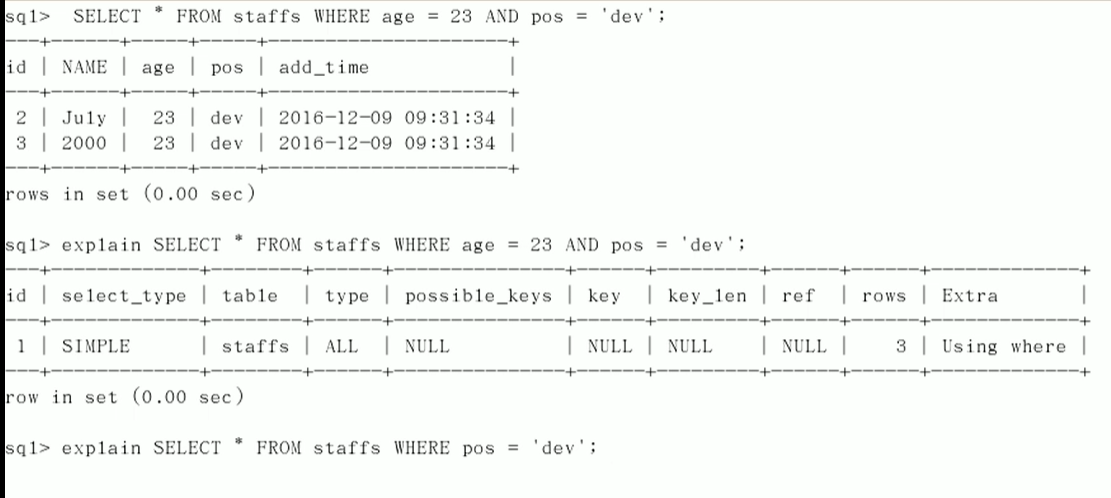
第一层索引没用上,梯子断裂,最佳左前缀原则
最佳左前缀原则
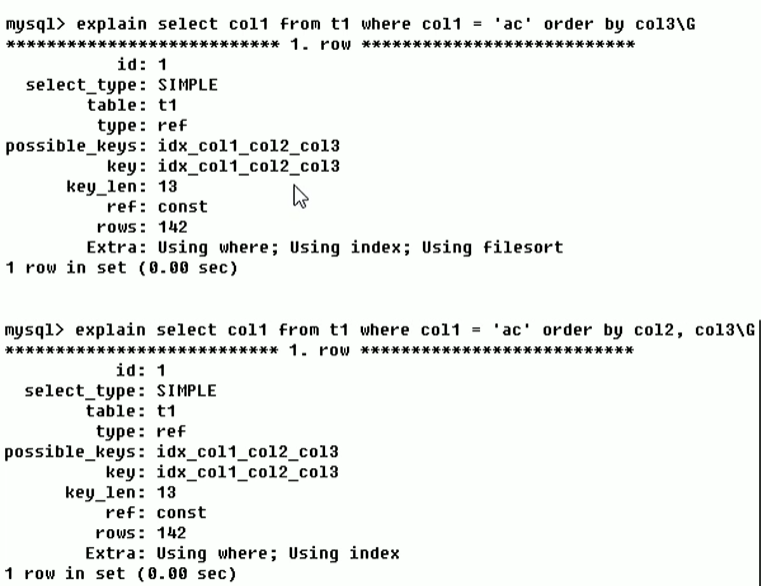
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
不在索引列上做任何操作
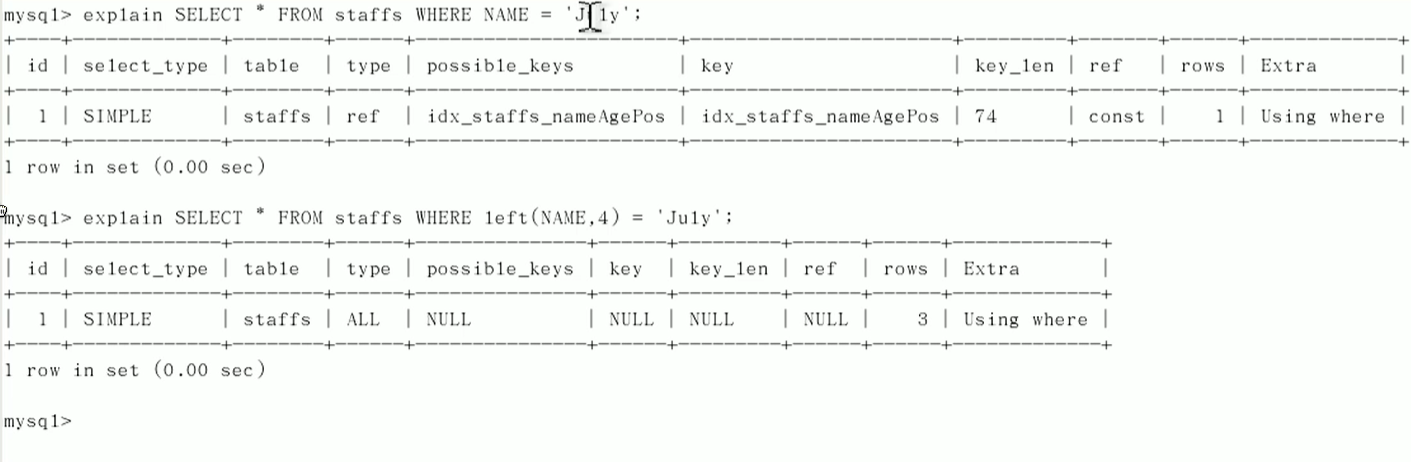
存储引擎不能使用索引中范围条件右边的列

范围后面的索引失效
尽量使用覆盖索引
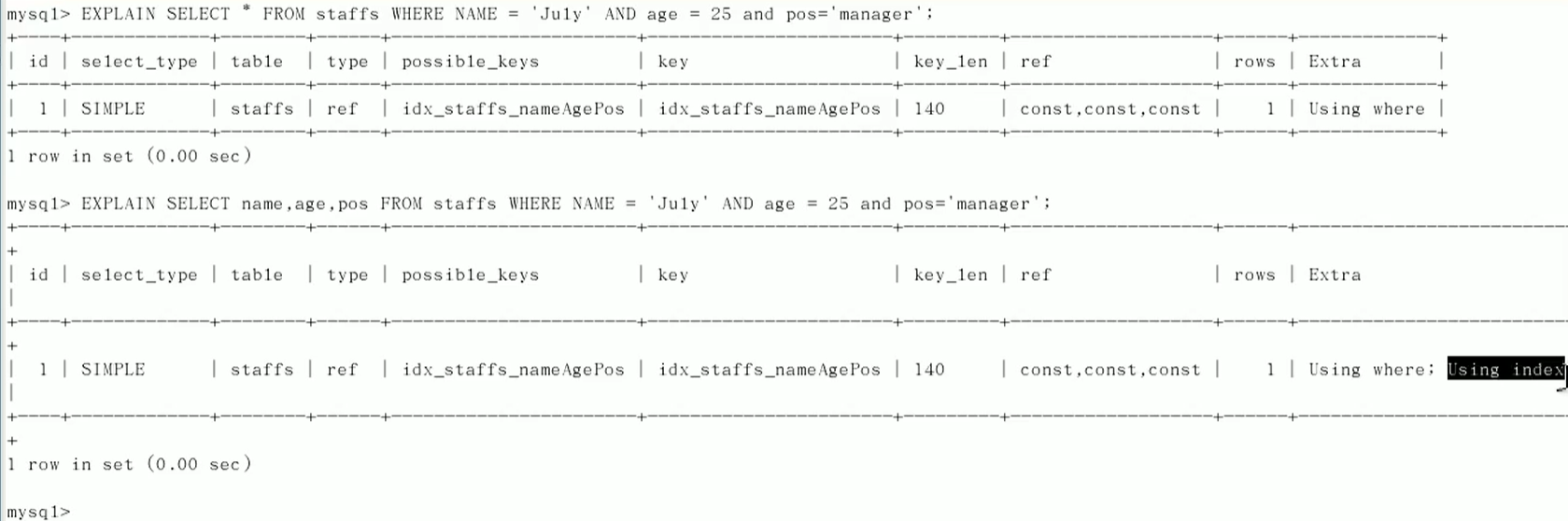
使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
is not,is not null无法使用索引
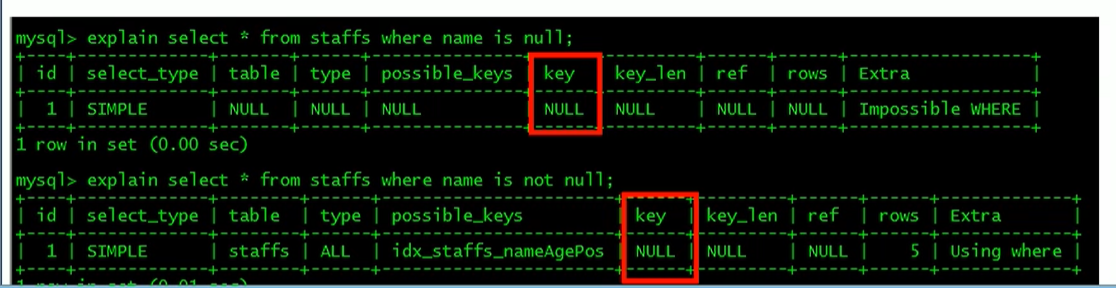
like以通配符开头使索引失效会变成全表扫描

要使用两边都带有通配符 ’ %XX% ’ 的解决方法:
创建覆盖索引;
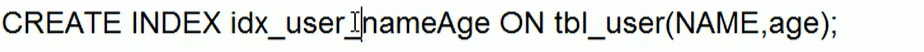
字符串不加单引号索引失效
少用or,用它来连接时索引失效
other:
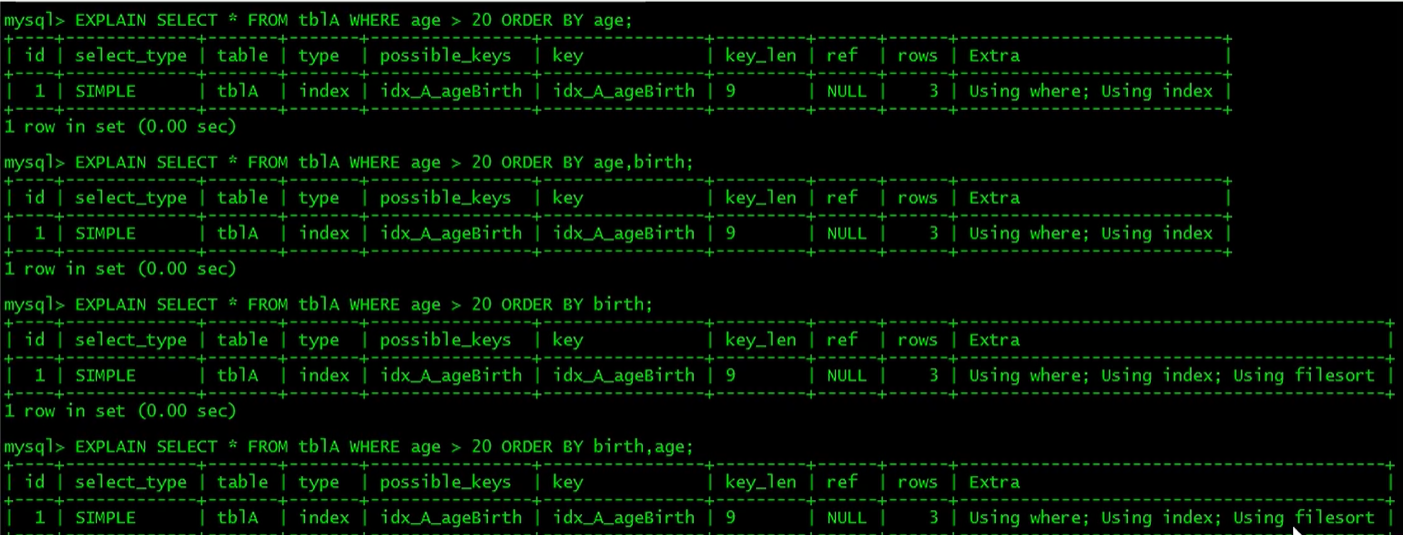
范围后索引断开,使用范围的字段也部分使用了索引.
用于字段排序的索引一定要按照建立索引的字段顺序.否则会产生filesort.
排序也会使用索引并且不会断开,但不显示在ref字段上.

分组之前必排序,会有临时表产生


查询截取分析
查询优化
小表驱动大表

“select 1 from"的1是什么都行,是个常量就行

in 和 exists

Order by关键字排序优化
order by子句,尽量使用index方式排序,避免使用filesort方式排序;

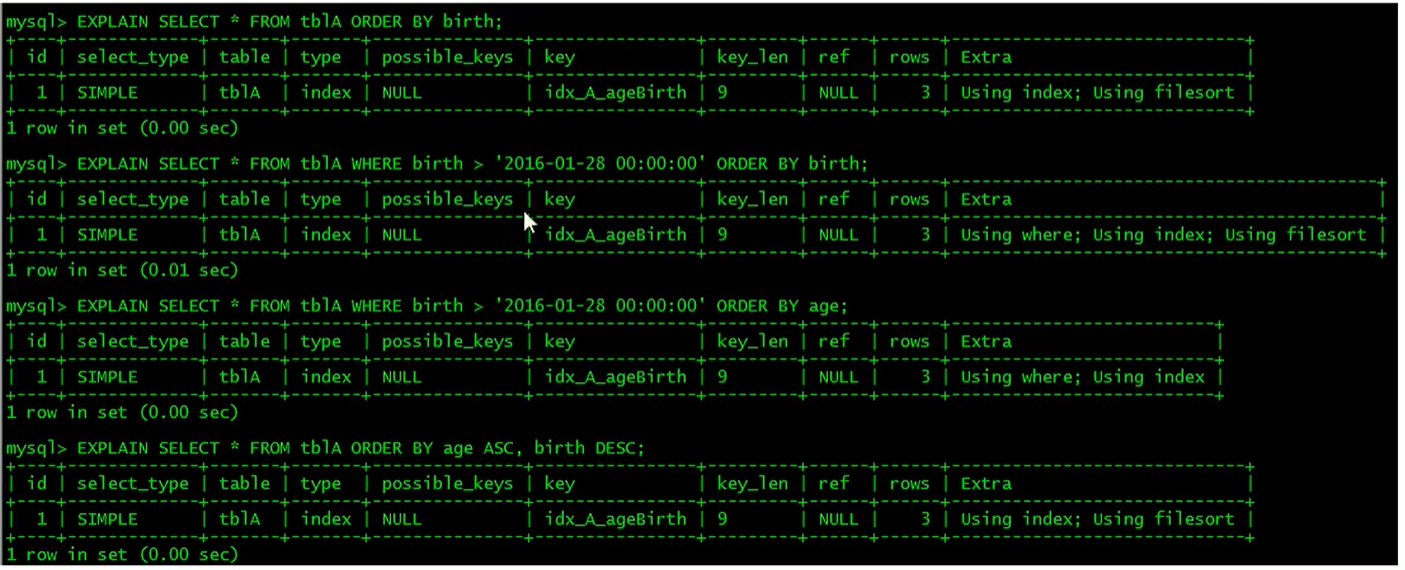
默认是升序。要不就全部升序,要不就全部降序
尽可能在索引树上完成排序操作,遵照索引建的最佳最前缀
如果不在索引列上,filesort有两种算法:
mysql就要启动双路排序和单路排序;
双路排序:MYSQL4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,读取行指针和orderby列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。
从磁盘取排序字段,在buffer进行排序,再从磁盘取其他字段。
取一批数据,要从磁盘进行了两次扫描,众所周知,I\O是很耗时的,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。
单路排序:从磁盘读取查询需要的所有列,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间。因为它把每一行都保存在内存了。
单路是后出的,总体而言好过双路。
单路也有问题:

优化策略
增大sort_buffer_size参数的设置
增大max_length_for_sort_data参数的设置


总结:

group by关键字优化

慢查询日志


查看是否开启
SHOW VARIABLES LIKE '%slow_query_log%';
默认是关闭的
开启
set global slow_query_log=1;
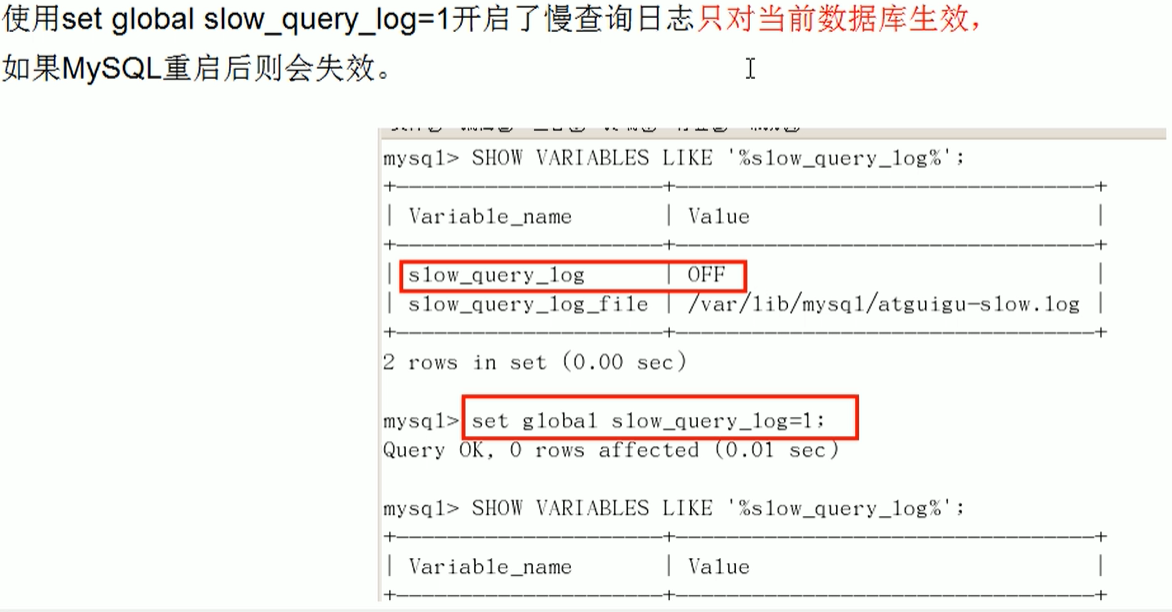


开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢?

设置慢的阈值时间:
set global long_query_time=3;
##需要重新连接或新开一个会话才能看到修改值.
SHOW VARIABLES LIKE 'long_query_time%';
##或者使用
SHOW global VARIABLES LIKE 'long_query_time';
模拟
select sleep(4);
查看日志
cat /var/lib/mysql/***.log
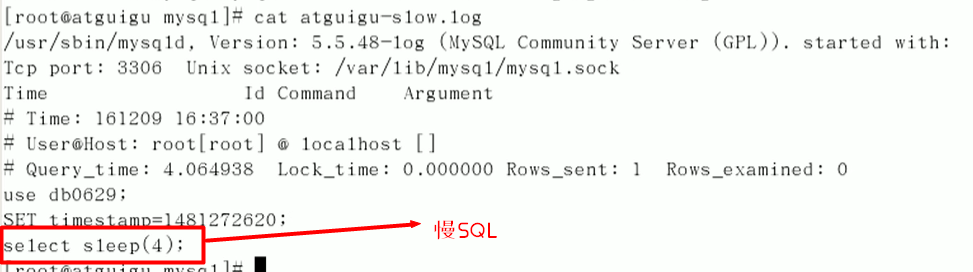
查询当前系统中有多少条慢查询记录

配置文件

日志分析工具
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MYSQL提供了日志分析工具mysqldumpslow.
使用帮助
mysqldumpslow --help

常用参考:

批量插入数据脚本

建数据库
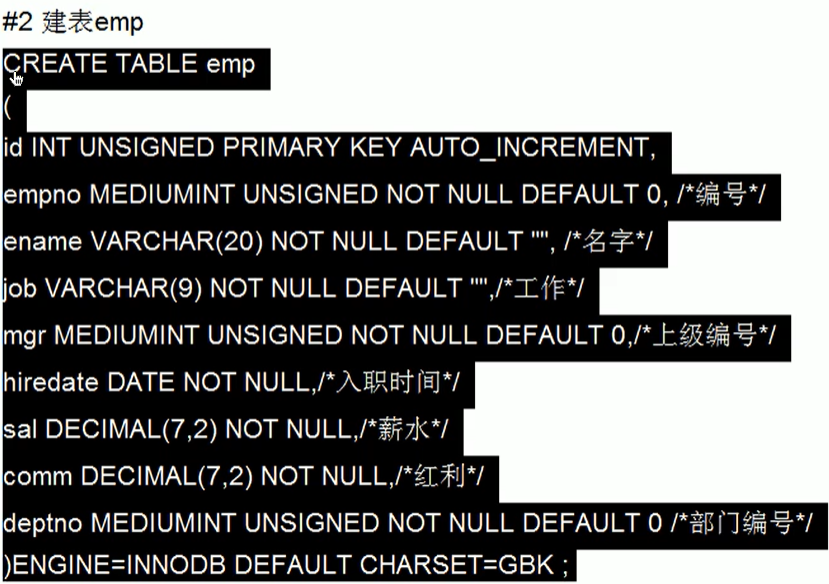
create database bigData; use bigData;建表dept
CREATE TABLE dept( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, ##部门编号 deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, ##部门名称 dname VARCHAR(20) NOT NULL DEFAULT "", ##楼层 loc VARCHAR(13) NOT NULL DEFAULT "" )ENGINE = INNODB DEFAULT CHARSET=GBK;建表emp
设置参数log_bin_trust_function_creators

随机产生部门字符串


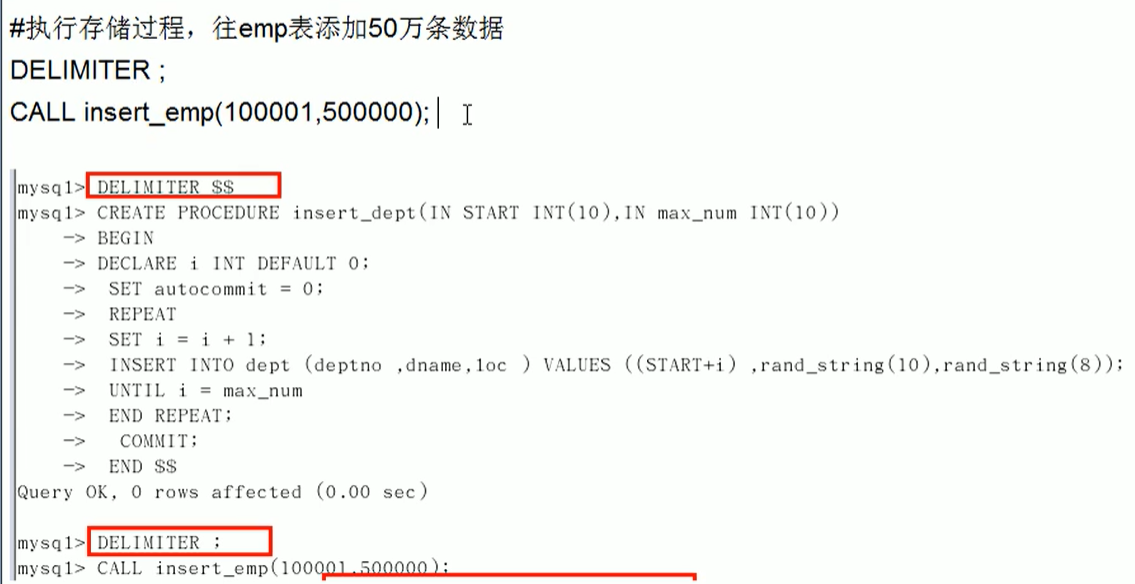
创建存储过程
创建往emp表插入数据的存储过程
function:有返回值
procedure:无返回值

创建往dept表插入数据的存储过程

调用存储过程
dept

emp
Show Profile
是mysql提供可以用来分析当前会话中语句执行的资源消耗情况.可以用于SQl的调优的测量.
默认情况下,参数处于关闭状态,并保存最近15次的运行结果.
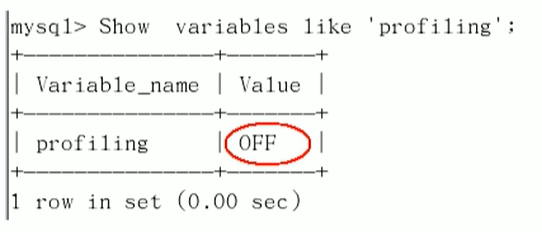
看看当前的mysql版本是否支持
Show variables like 'profiling';
或者Show variables like 'profiling%';
##默认是关闭的,使用前需要开启
开启功能

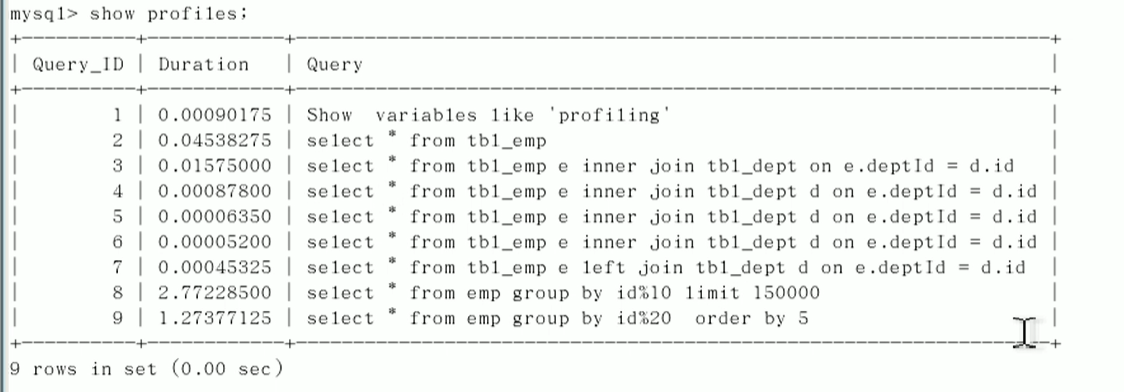
运行SQL
select * from emp group by id%10 limit 150000;
select * from emp group by id%20 order by 5;
查看结果
show profiles;
诊断SQL
show profile cpu, block io for query ID(上一步前面的问题SQL数字号码);

需要注意的:

全局查询日志
永远不要在生产环境开启这个功能,仅在测试环境使用.
配置开启:

编码开启:

数据库锁
锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源(如CPU,RAM,I/O等)的争用以外,数据也是供许多用户共享的资源.如何保证数据并发访问的一致性、有效性hi所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
锁的分类
从对数据操作的类型(读\写)分
读锁(共享锁): 针对同一份数据,多个读操作可以同时进行而不会互相影响
写锁(排他锁): 当前写操作没有完成前,它会阻断其他写锁和读锁;
从对数据操作的粒度分
表锁
行锁
MYSQL锁机制
三锁 ↓
表锁(偏读)
特点:偏向MyISAM存储引擎,开销小,加锁快;无死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低
案例:


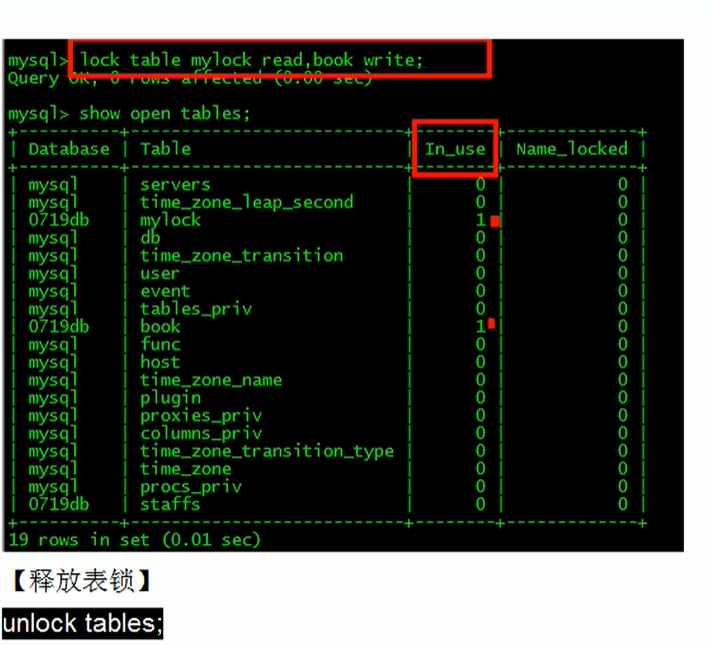
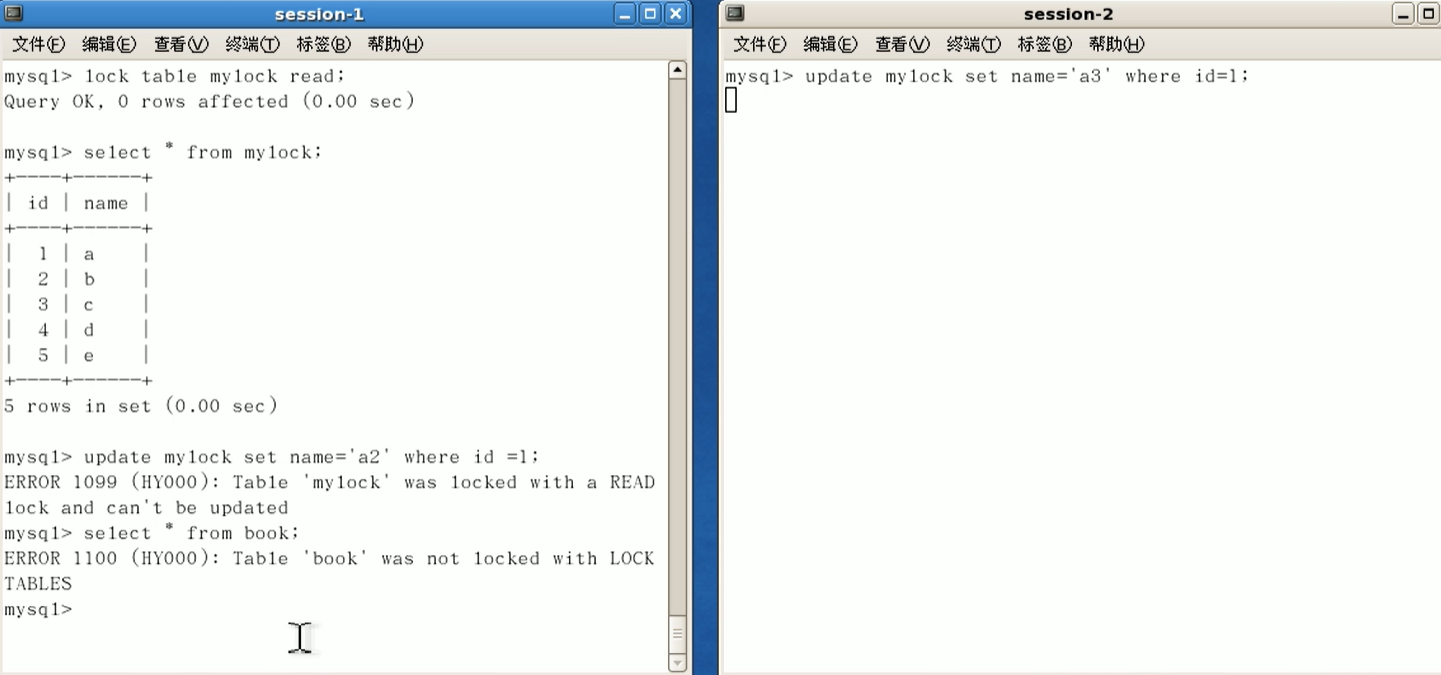
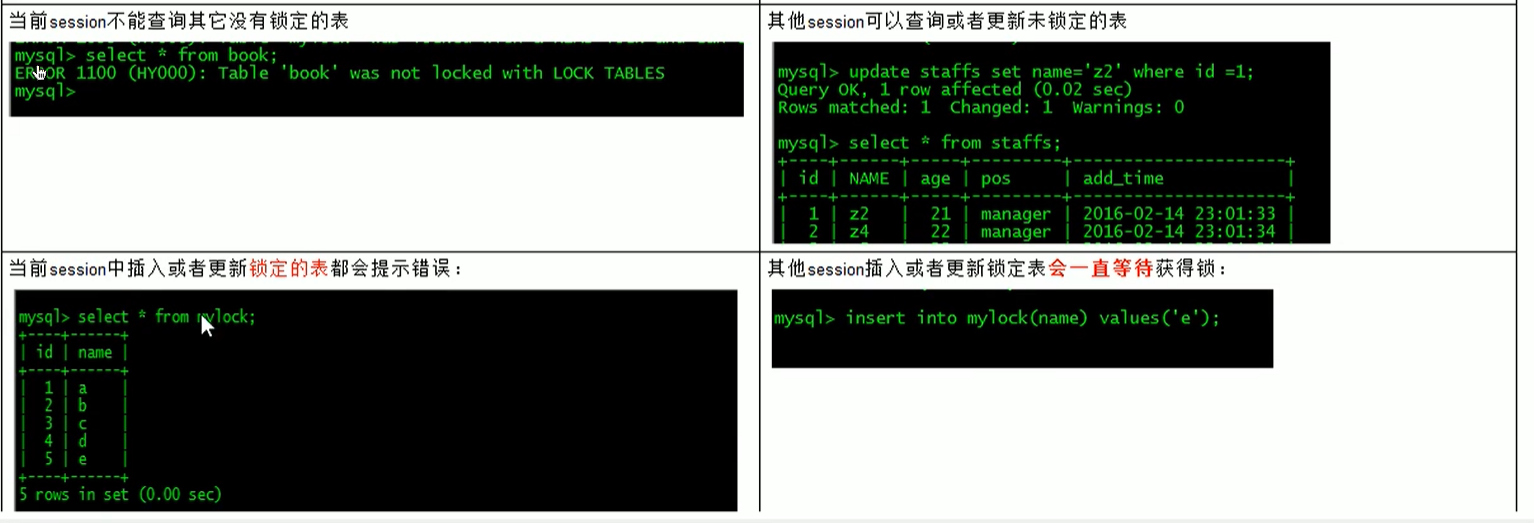
读操作时共享的,会话1和2都可以读mylock;
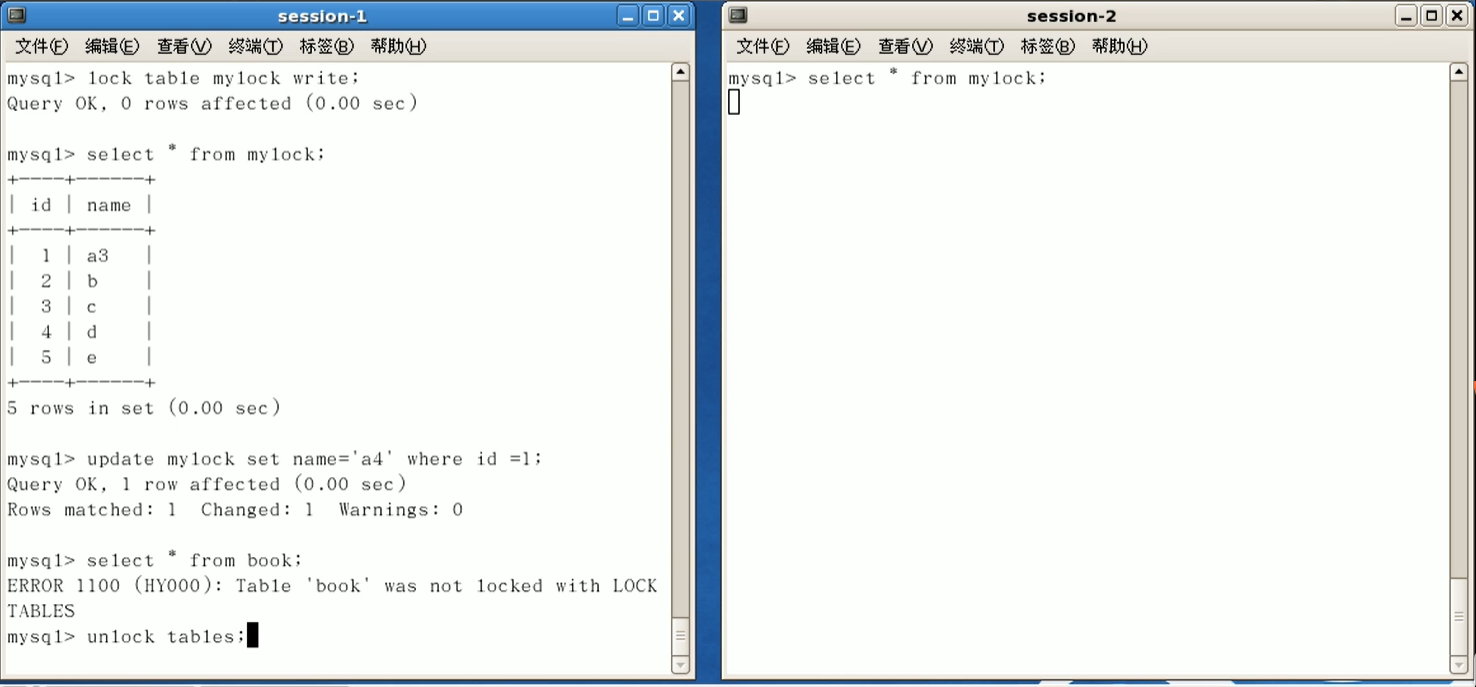
会话1不能更新表;
会话1只能读加读锁的mylock表,不能读其他表(book);会话2可以读其他表.
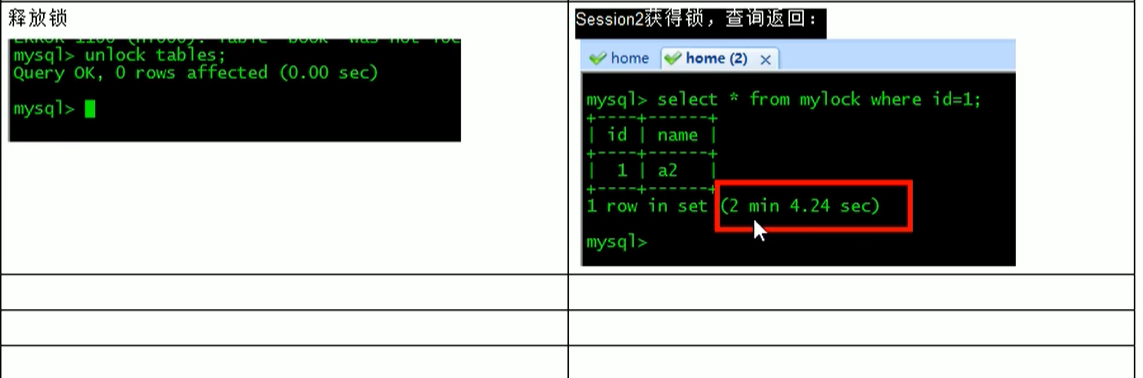
会话2如果要更新表,会形成阻塞,要等待锁的释放(unlock tables)


写锁

其他会话读被锁的表会阻塞;
结论: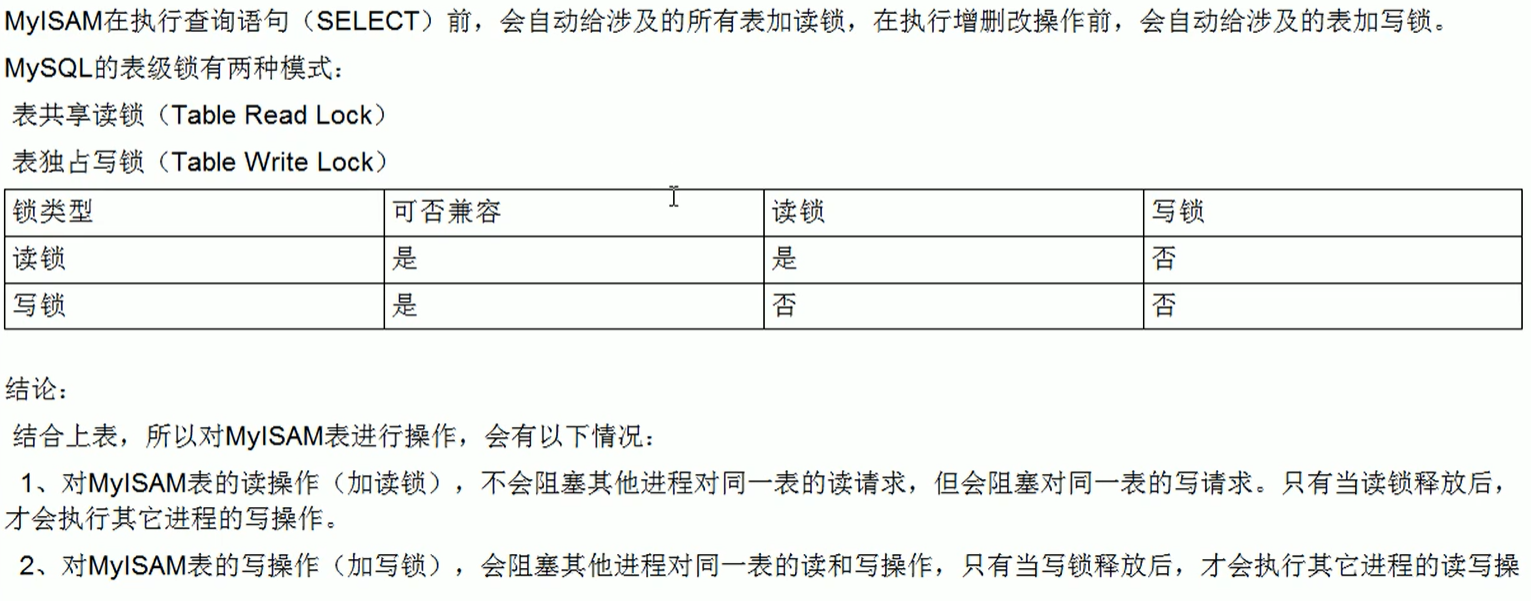
简而言之,就是读锁会阻塞写,但是不会堵塞读,而写锁则会把读和写都堵塞.
看看哪些表被锁了
show open tables;
如何分析表锁定
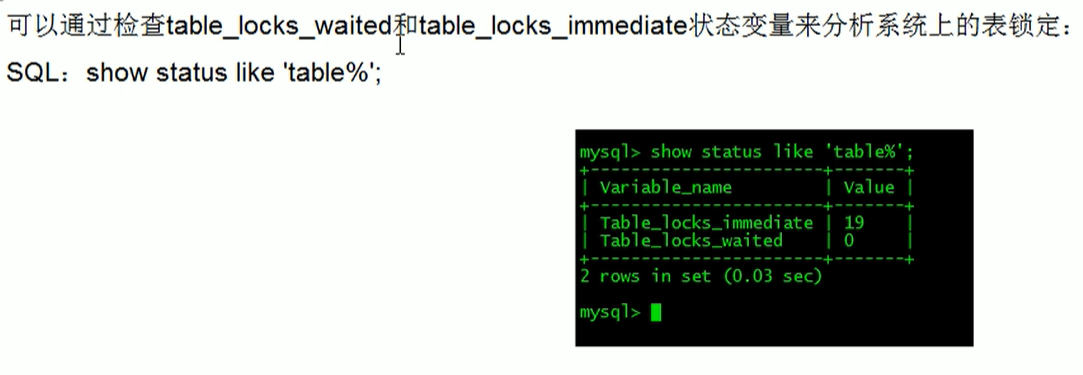

行锁(偏写)
特点:偏向InnoDB存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
InnoDB与MyISAM的最大不同也有两点:
一是支持事务(TRANSACTION);
二是采用了行级锁.
事务(Transaction)及其ACID属性

并发处理事务带来的问题
更新丢失(Lost Update)
脏读(Dirty Reads)
不可重复读(Non-Repeatable Reads)
幻读(Planttom Reads)




事务隔离级别;

默认级别是Repeatable read
案例分析:
建表

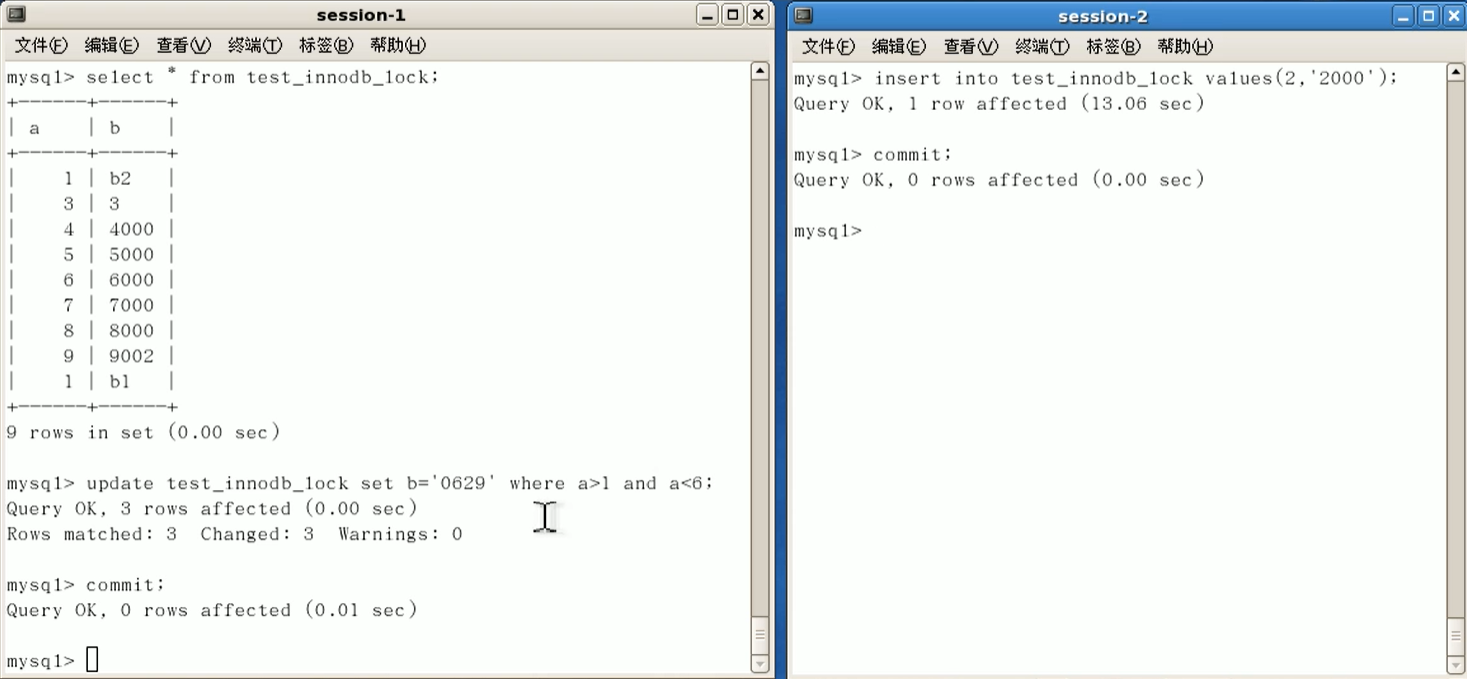
select * from test_innodb_lock;
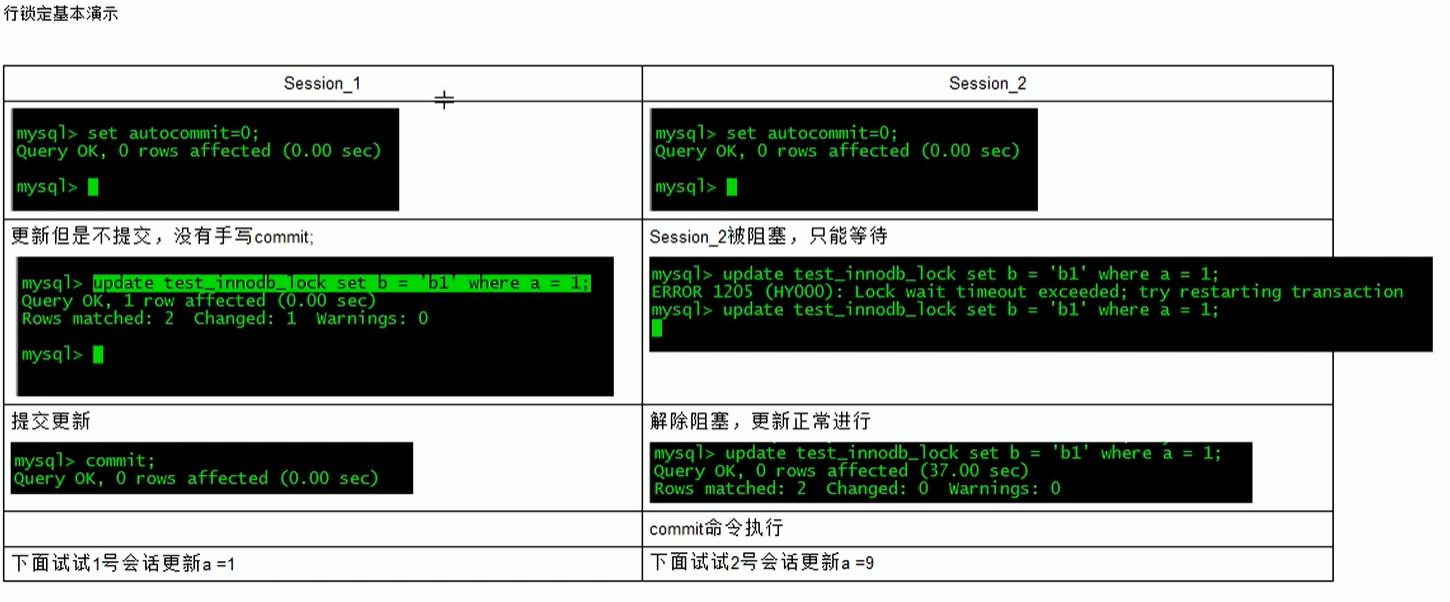
在没session1和2提交commit之前,session-2读不到修改的数据.
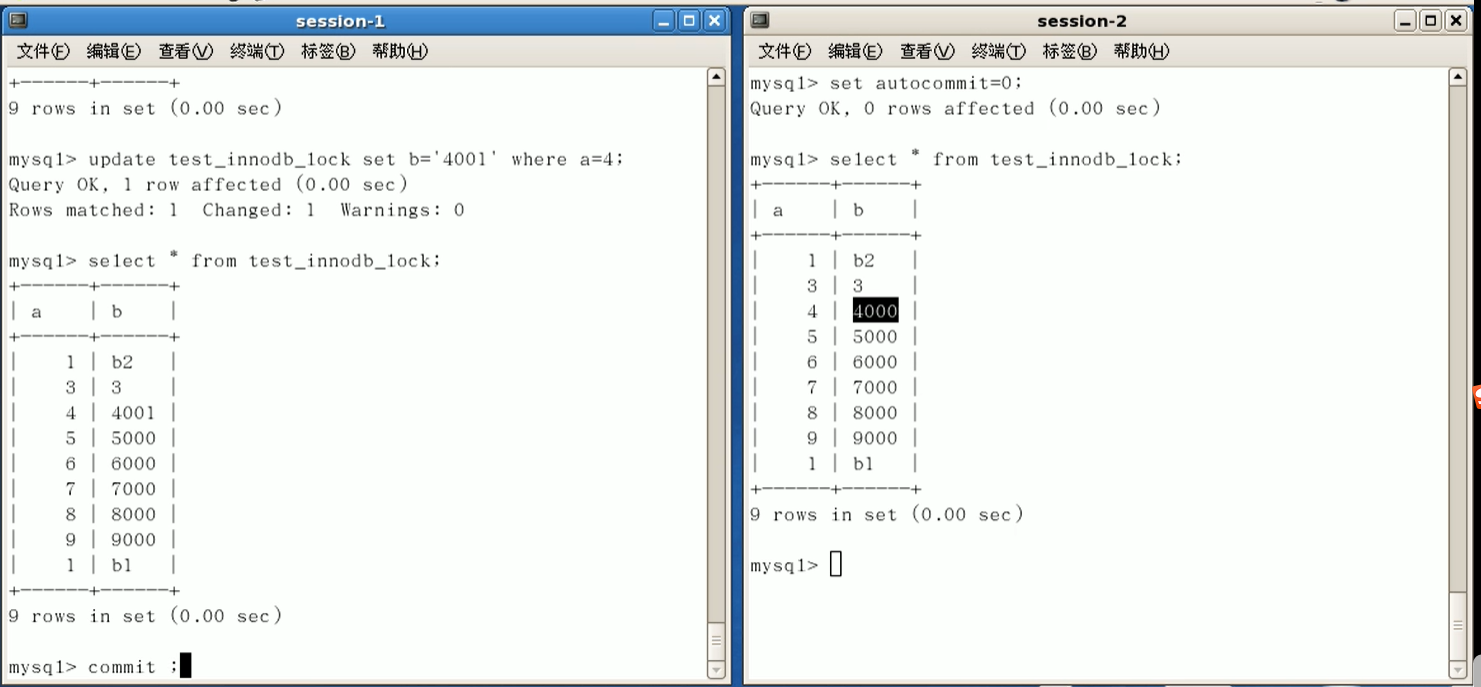
操作不同行,不会阻塞

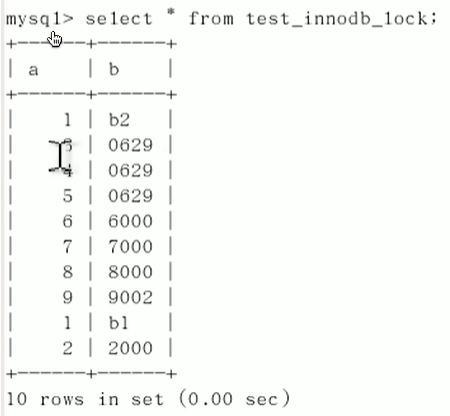
无索引行锁变表锁;
类型转换,索引失效: (b=‘4000’)
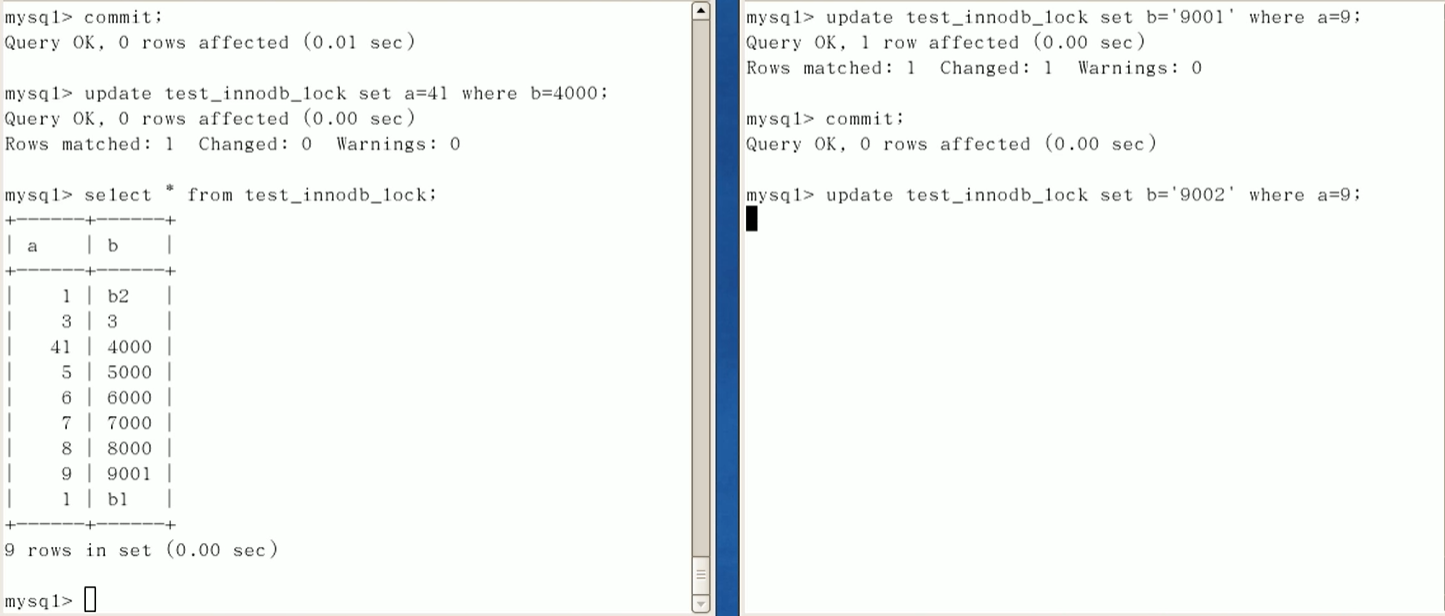
行锁变表锁,造成阻塞.
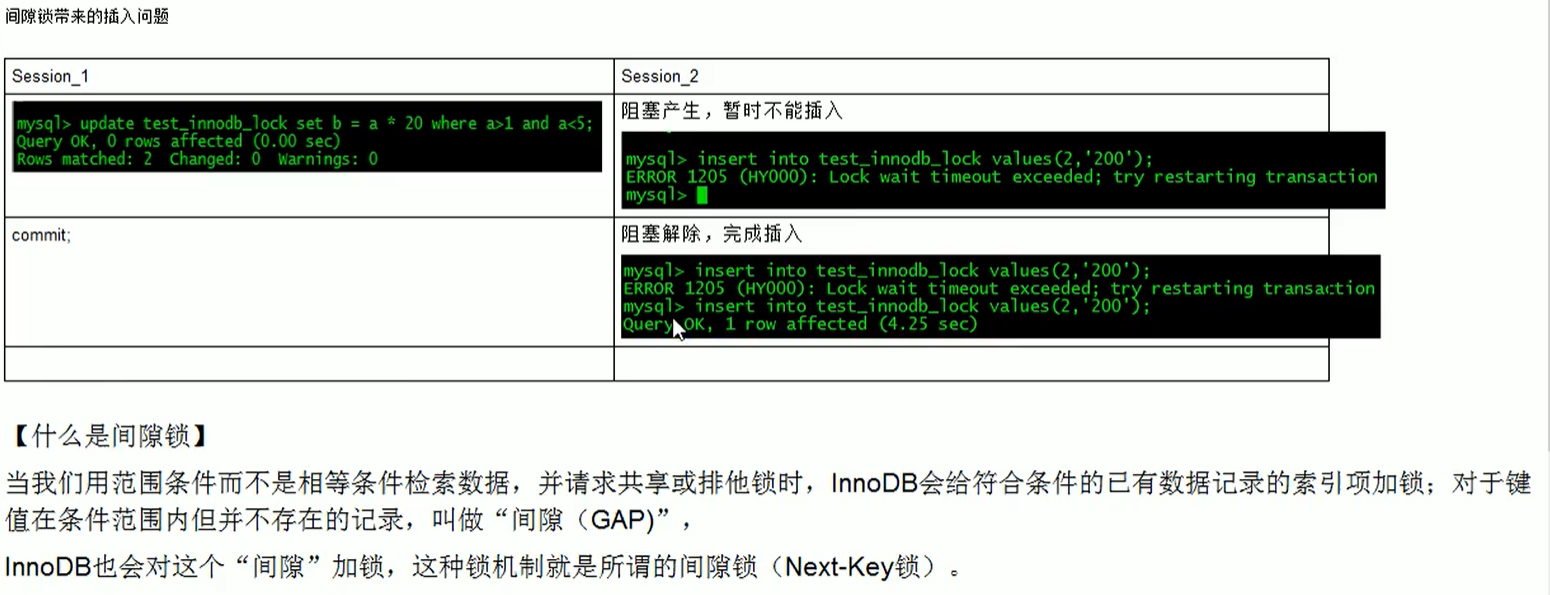
间隙锁的危害
session2会阻塞,

如何锁定一行
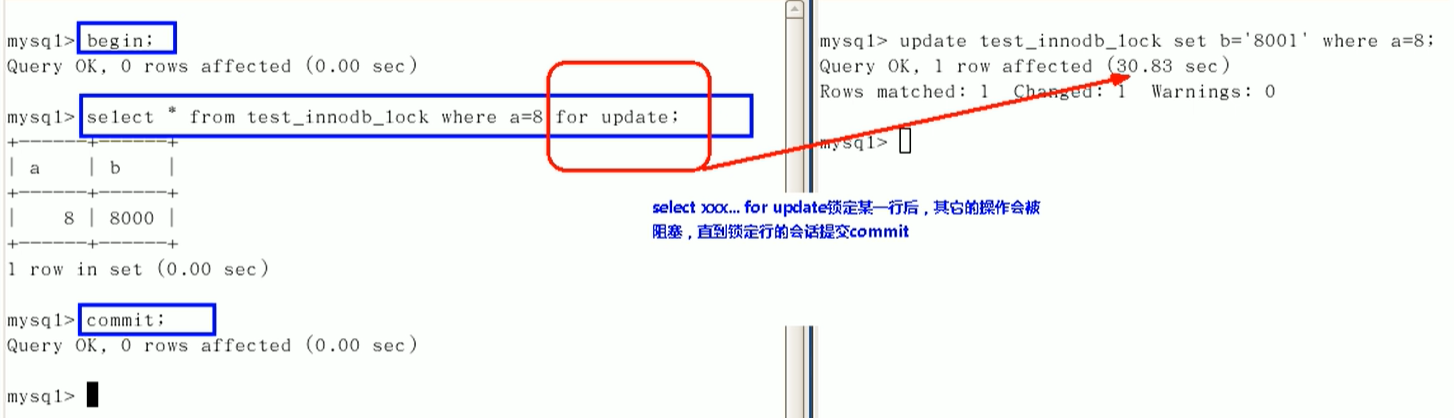
行锁总结

如何分析行锁定
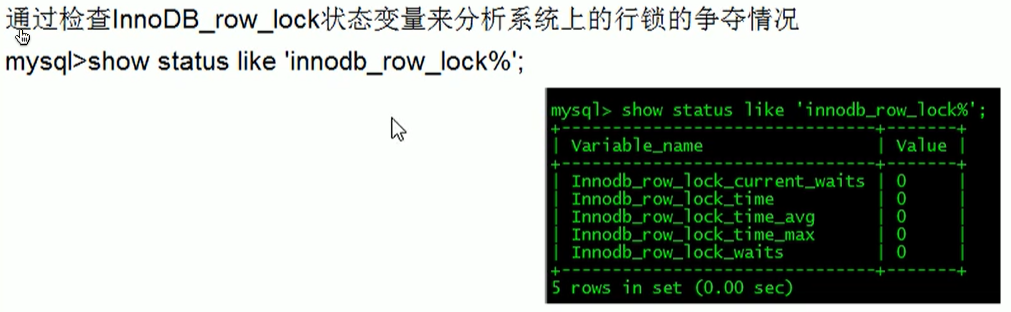


优化建议:

页锁
开销和加锁时间界于表锁和行锁之间,会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般.
主从复制
复制的基本原理:
slave会从master读取binlog来进行数据同步
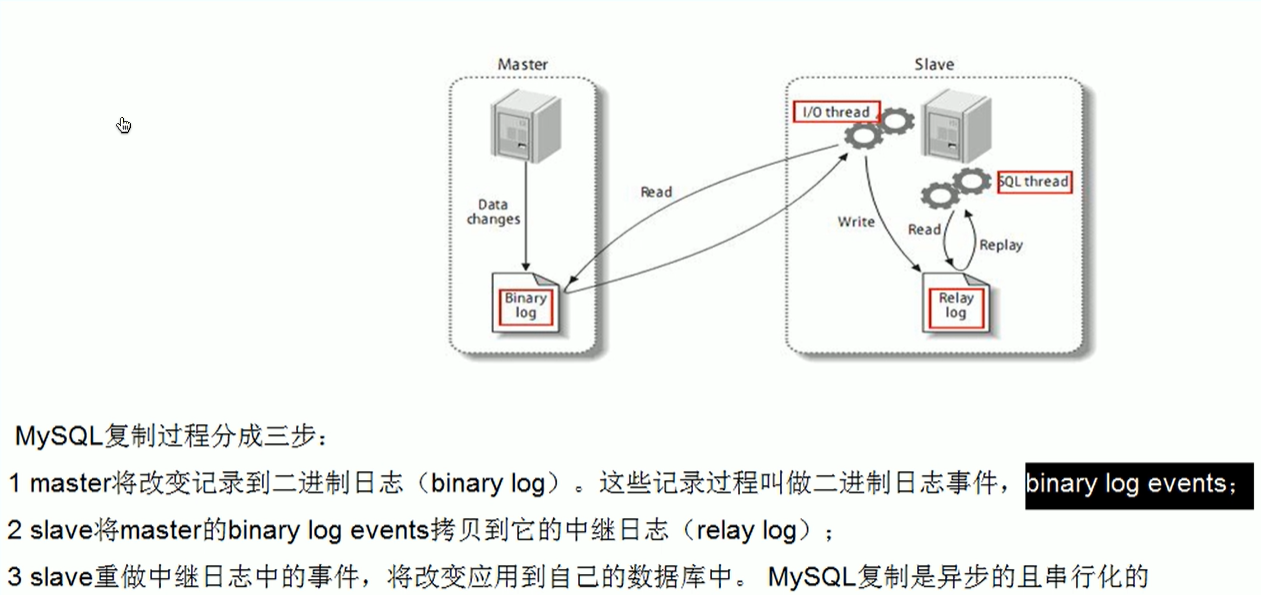
复制的基本原则:
每个slave只有一个master
每个slave只能有一个唯一的服务器ID
每个master可以有多个slave
复制的最大问题:
延时
一主一从常见配置:
mysql版本要一致且后台以服务运行. 网段要相通ping
主从都配置在[mysqld]结点下,都是小写.
主机(window)修改my.ini配置文件
主服务器唯一ID[
必须]
- server-id = 1
启动二进制日志[
必须]log-bin=自己本地的路径/mysqlbin
log-bin=D:/devSoft/MySQLServer5.5/data/mysqlbin
启用错误日志[
可选]log-err = 自己本地的路径/mysqlerr
log-err = D:/devSoft/MySQLServer5.5/data/mysqlerr
根目录[
可选]basedir = “自己本地路径”
basedir = “D:/devSoft/MySQLServer5.5/”
临时目录[
可选]tmpdir = “自己本地路径”
tmpdir = “D:/devSoft/MySQLServer5.5/”
数据目录[
可选]datadir = “自己本地路径/Data/”
datadir = “D:/devSoft/MySQLServer5.5/Data/”
read-only=0
主机, 读写都可以
设置不要复制的数据库[
可选]binlog-ignore-db=mysql
设置需要复制的数据库[
可选]binlog-do-db=需要复制的主数据库名字
从机(Linux)修改my.cnf配置文件
从服务器唯一ID[
必须]注释 server-id=1
下翻,取消注释server-id = 2
启动二进制日志[
可选]因修改过配置文件,请主机+从机都重启后台mysql服务
service mysql stop service mysql start ps -ef|grep mysql主机从机都关闭防火墙
window 手动关闭 linux从机 service iptables stop在window主机上建立账户并授权slave
mysql
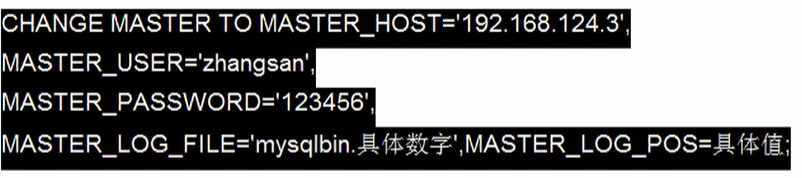
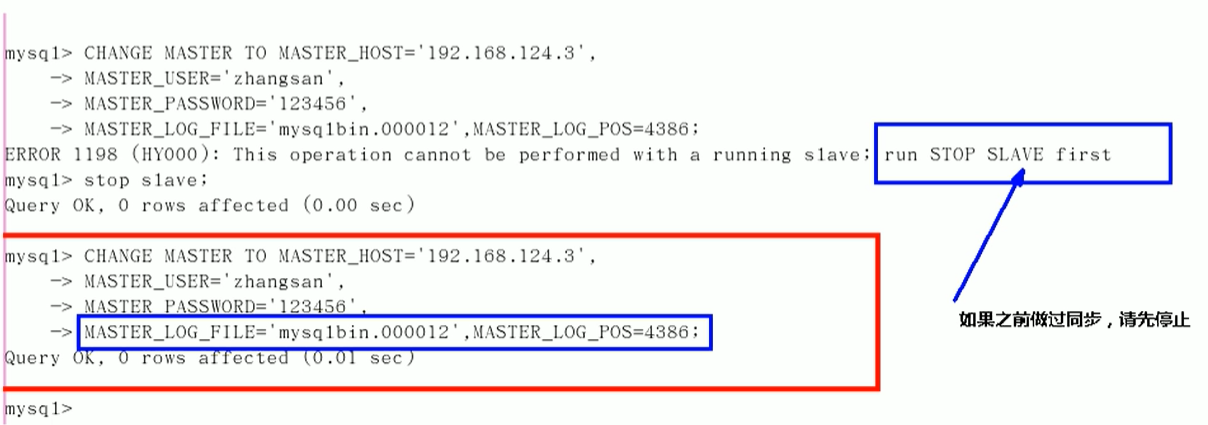
flush privileges查看master的状态
show master status;记录下File和Position的值.
Position在后面使用后会有变化
在linux从机上配置需要复制的主机
启动从服务器复制功能
start slave;show slave status\G 下面两个参数都是Yes,则说明主从配置成功. Slave_IO_Running:Yes Slave_SQL_Running:Yes主机建库,建表
insert记录
从机有记录
停止从机复制功能
stop slave;