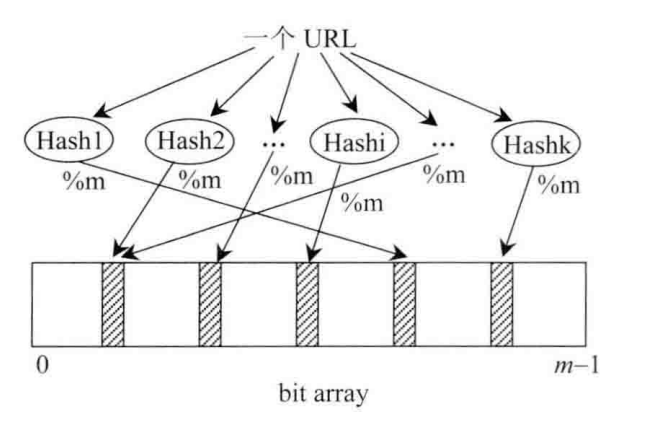
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
import java.util.ArrayList;
import java.util.BitSet;
import java.util.List;
public class BloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 };
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
// 内部类,simpleHash
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
public static void main(String[] args) {
BloomFilter bf = new BloomFilter();
List<String> strs = new ArrayList<String>();
strs.add("123456");
strs.add("hello word");
strs.add("transDocId");
strs.add("123456");
strs.add("transDocId");
strs.add("hello word");
strs.add("test");
for (int i=0;i<strs.size();i++) {
String s = strs.get(i);
boolean bl = bf.contains(s);
if(bl){
System.out.println(i+","+s);
}else{
bf.add(s);
}
}
}
}
布隆过滤器的应用
黑名单校验
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,再收到邮件时,判断邮件地址是否在布隆过滤器中即可。
解决缓存穿透的问题
一般情况下,先查询缓存是否有该条数据,缓存中没有时,再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。缓存穿透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题,把已存在数据的key存在布隆过滤器中。当有新的请求时,先到布隆过滤器中查询是否存在,如果不存在该条数据直接返回;如果存在该条数据再查询缓存查询数据库。
Redisson实现布隆过滤器在亿级流量系统的应用
**场景:**正常redis有1000条缓存数据,忽然遭到爬虫/流量攻击攻击,大量不存在的于redis的数据批量查询, 由于redis不存在这些数据,会到数据库进行查询。由于数据库对于瞬时高并发访问的承载能力弱,所以可能 对数据库造成影响,甚至崩溃。 绕过redis服务器进入数据库查询的方式叫做缓存穿透。
缓存穿透攻击:
指恶意用户在短时间内大量查询不存在的数据,导致大量请求在被送达数据库进行查询, 当请求数量超过数据库负载上限时,使系统响应出现高延迟甚至瘫痪的行为。
如何预防缓存穿透?布隆过滤器。
布隆过滤器:由一个很长的二进制向量和一系列随机映射函数组成,可以用于检索一个元素是否在一个集合中。 特点: 1.一定的误识别率(即某一元素存在于某集合中,但是实际上该元素并不在集合中) 2.但是没有识别错误的情形(即如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。 也就是:我说你不在你就一定不在,我说在,可能不在。 3.删除困难
了解hash: Hash (散列函数):是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值。 由于这种转换,可能存在 不同的输入可能会散列成相同的输出。 Hash算法可以将一个数据转换为一个标志,这个标志,就是视频说的hash,hash后若不存在,就由0变为1。存在,不变。
视频hash1(858),hash2(858),hash3(858)的原理是: Hash面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素。显然这就不叫空间有效了(Space-efficient)。 解决方法也简单,就是使用多个 Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。 (我搬运的,前半句我看不懂,只看懂后半句,理解就是:hash有冲突的可能,多个hash减少冲突率。原来1个说在,但可能不在。若2个,1个说在,另一个说不在,就肯定不在)
减少误判的措施:
1.增加二进制数组位数。 2.增加Hash次数。
开发中如何使用? redisson组件内置布隆过滤器,导入直接使用。
项目中如何使用: 应用启动时初始化布隆过滤器(将商品在布隆过滤器中先从0转换成1) 用户请求时判断布隆过滤器是否有编号,若布隆过滤器有,读取redis,若redis没有,则读取数据库,载入redis缓存。 若布隆过滤器没有,返回数据不存在消息。
假如布隆过滤器初始化后,有商品被删除了, 怎么办? 布隆过滤器某一位二进制可能被多个编号hash引用(看hash的特点:不同的输入可能会散列成相同的输出) 所以,不能直接处理删除布隆过滤器的数据。 解决方案: 1.定时异步重建布隆过滤器 2.计数BloomFilter(可以知道该位被几个引用)
我一开始觉得,删就删了呗,管他干嘛,但是不管他,冲突率会高,处理后,这个数据就不会再引起冲突。 即:A商品被删后,当你查询A商品时,布隆过滤器说他在(布隆过滤器特点:我说你不在你就一定不在,我说在,可能不在),那我就要去redis查,但实际数据库查不到这个A商品,redis也没有。 这就存在冲突了。如果处理之后,布隆过滤器说不在就不在。
Redisson
1.引入maven依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.1</version>
</dependency>
2、关于redis的配置
redis配置:
#客户端超时时间单位是毫秒 默认是2000
redis.timeout=10000
#最大空闲数
redis.maxIdle=300
#连接池的最大数据库连接数。设为0表示无限制,如果是jedis 2.4以后用redis.maxTotal
#redis.maxActive=600
#控制一个pool可分配多少个jedis实例,用来替换上面的redis.maxActive,如果是jedis 2.4以后用该属性
redis.maxTotal=2000
#最大建立连接等待时间。如果超过此时间将接到异常。设为-1表示无限制。
redis.maxWaitMillis=1000
redis.nodes=192.168.25.128:7000,192.168.25.128:7001,192.168.25.128:7002,192.168.25.128:7003,192.168.25.128:7004,192.168.25.128:7005,192.168.25.128:7006,192.168.25.128:7007
3、配置文件的书写
@Configuration
@PropertySource("classpath:conf/redis.properties")
public class RedisConfig {
@Value("${redis.nodes}")
private String clusterNodes;
@Bean
public RedissonClient getBloomFilter(){
Config config = new Config();
ClusterServersConfig clusterServersConfig = config.useClusterServers();
String[] cNodes = clusterNodes.split(",");
//分割出集群节点
for (String node : cNodes) {
clusterServersConfig.addNodeAddress("redis://" + node);
}
return Redisson.create(config);
}
}
4、service的的代码
public interface RedissonBloomFilterService {
/**
* 初始化一个布隆过滤器
*
* @param key key
* @param expireDate 过期时间长度
* @param timeUnit 过期时间单位
* @return 是否创建成功
*/
boolean initNewFilter(String key, Long expireDate, TimeUnit timeUnit, long expectedInsertions, double falseProbability);
/**
* 添加value到今天布隆过滤器
* @param key key
* @param value 需要添加到过滤器的值
* @return 是否添加成功
*/
boolean add(final String key, final String value);
/**
* 添加value到今天布隆过滤器
* @param key key
* @param list 需要添加到过滤器的值
* @return 是否添加成功
*/
boolean add(final String key, final List<String> list);
/**
* 判断对应key是否有value值
* @param key key
* @param value 对应key的value值
* @return 应key是否有value值
*/
boolean containsValue(final String key, final String value);
/**
* 查看是否存在key值
* @param key key
* @return 是否有key值
*/
boolean containKey(final String key);
}
实现类:
@Slf4j
@Service
public class RedissonBloomServiceImpl implements RedissonBloomFilterService {
public static String prefix = "redission_bf_";
private static DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyyMMdd");
private static final int TIME_FORMAT_LENGTH = 8;
@Resource
private RedissonClient redissonClient;
/**
* 1、第一层的key为传入key值
* 2、第二次key为 prefix + key+20200718
*/
private Map<String, ConcurrentHashMap<String, RBloomFilter>> bloomFilterMap = new ConcurrentHashMap<>();
@Override
public synchronized boolean initNewFilter(String key, Long expireDate, TimeUnit timeUnit, long expectedInsertions, double falseProbability) {
String timeFormatter = formatter.format(LocalDateTime.now());
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(prefix + timeFormatter + key);
//初始化布隆过滤器
boolean isSuccess = bloomFilter.tryInit(expectedInsertions, falseProbability);
if (isSuccess) {
//设置过期时间
bloomFilter.expire(expireDate, timeUnit);
//设置过期监听器
bloomFilter.addListener(new ExpiredObjectListener() {
@Override
public void onExpired(String key) {
log.info("onExpired callback running key is {}", key);
if (key.startsWith(prefix)) {
String firstKey = key.substring(prefix.length() + TIME_FORMAT_LENGTH);
ConcurrentHashMap<String, RBloomFilter> map = bloomFilterMap.get(firstKey);
if (Objects.isNull(map)) {
log.warn("listener callback key is empty key is {}", key);
return;
}
map.remove(key);
}
}
});
ConcurrentHashMap<String, RBloomFilter> map = bloomFilterMap.computeIfAbsent(key, (k) -> {
return new ConcurrentHashMap<String, RBloomFilter>(4);
});
map.put(prefix + timeFormatter + key, bloomFilter);
isSuccess = true;
}else {
log.error("initNewFilter fail key is {}", key);
}
return isSuccess;
}
@Override
public boolean add(String key, String value) {
String timeFormatter = formatter.format(LocalDateTime.now());
ConcurrentHashMap<String, RBloomFilter> map = bloomFilterMap.get(key);
if (Objects.isNull(map)) {
log.error("add name key one value is null, name is {},value is {}", key, value);
return false;
}
RBloomFilter rBloomFilter = map.get(prefix + timeFormatter + key);
if (Objects.isNull(rBloomFilter)) {
log.error("add name key one value is null, name is {},redis key is {},value is {}", key, prefix + timeFormatter + key, value);
return false;
}
return rBloomFilter.add(value);
}
@Override
public boolean add(String key, List<String> list) {
String timeFormatter = formatter.format(LocalDateTime.now());
ConcurrentHashMap<String, RBloomFilter> map = bloomFilterMap.get(key);
if (Objects.isNull(map)) {
log.error("add name key list value is null, name is {}", key);
return false;
}
RBloomFilter rBloomFilter = map.get(prefix + timeFormatter + key);
if (Objects.isNull(rBloomFilter)) {
log.error("add name key list value is null, name is {},redis key is {}", key,prefix + timeFormatter + key);
return false;
}
list.forEach(value -> rBloomFilter.add(value));
return true;
}
@Override
public boolean containsValue(String key, String value) {
ConcurrentHashMap<String, RBloomFilter> map = bloomFilterMap.get(key);
if (Objects.isNull(map)) {
log.error("containsValue key is exist, key is {}", key);
return false;
}
for (Map.Entry<String, RBloomFilter> entry : map.entrySet()) {
if (entry.getValue().contains(value)) {
return true;
}
}
return false;
}
@Override
public boolean containKey(String key) {
return bloomFilterMap.containsKey(key);
}
}
测试类:
@Test
public void testRedissonBloom() throws InterruptedException {
//创建过滤器
redissonBloomFilterService.initNewFilter("bloomkey1", 60L, SECONDS, 50, 0.1);
redissonBloomFilterService.initNewFilter("bloomkey2", 60L, SECONDS, 50, 0.1);
for (int i = 0; i < 50; i++) {
redissonBloomFilterService.add("bloomkey1", "" + i);
if (i > 30) {
redissonBloomFilterService.add("bloomkey2", "" + i);
}
}
int j1 = 0;
int j2 = 0;
for (int i = 0; i < 100; i++) {
boolean exists = redissonBloomFilterService.containsValue("bloomkey1", "" + i);
if (exists) {
System.out.println("bloomkey1有误判" + (++j1) + "i是" + i);
}
boolean exists2 = redissonBloomFilterService.containsValue("bloomkey2", "" + i);
if (exists2) {
System.out.println("bloomkey2" +
"有误判" + (++j2) + "i是" + i);
}
}
CountDownLatch beginCount = new CountDownLatch(1);
beginCount.await();
}